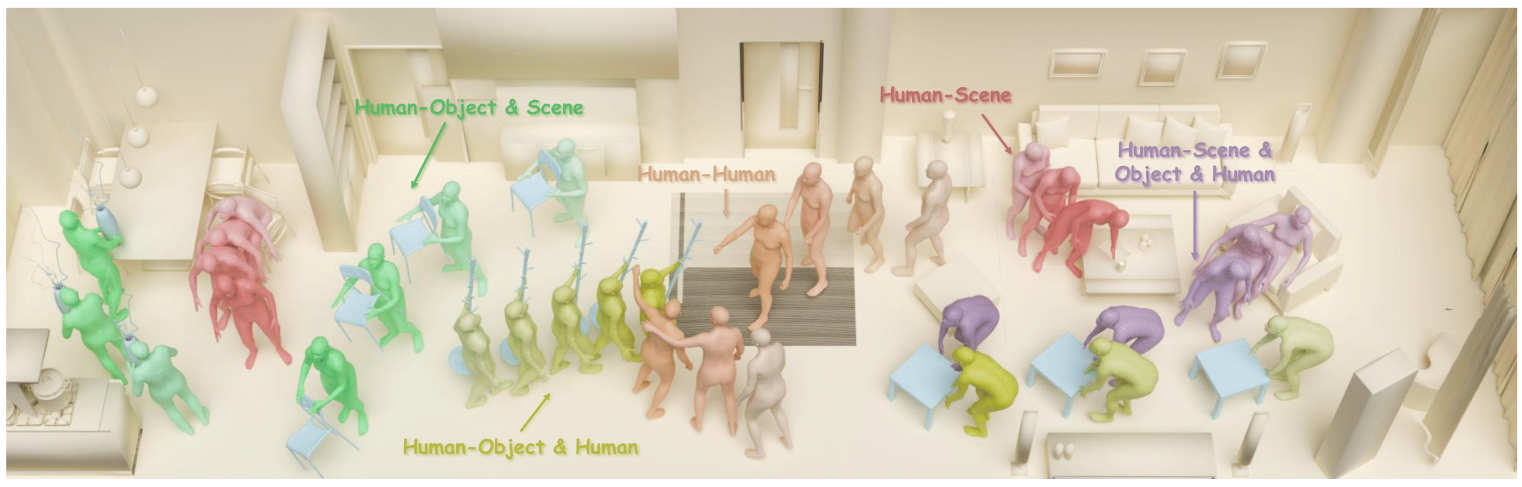
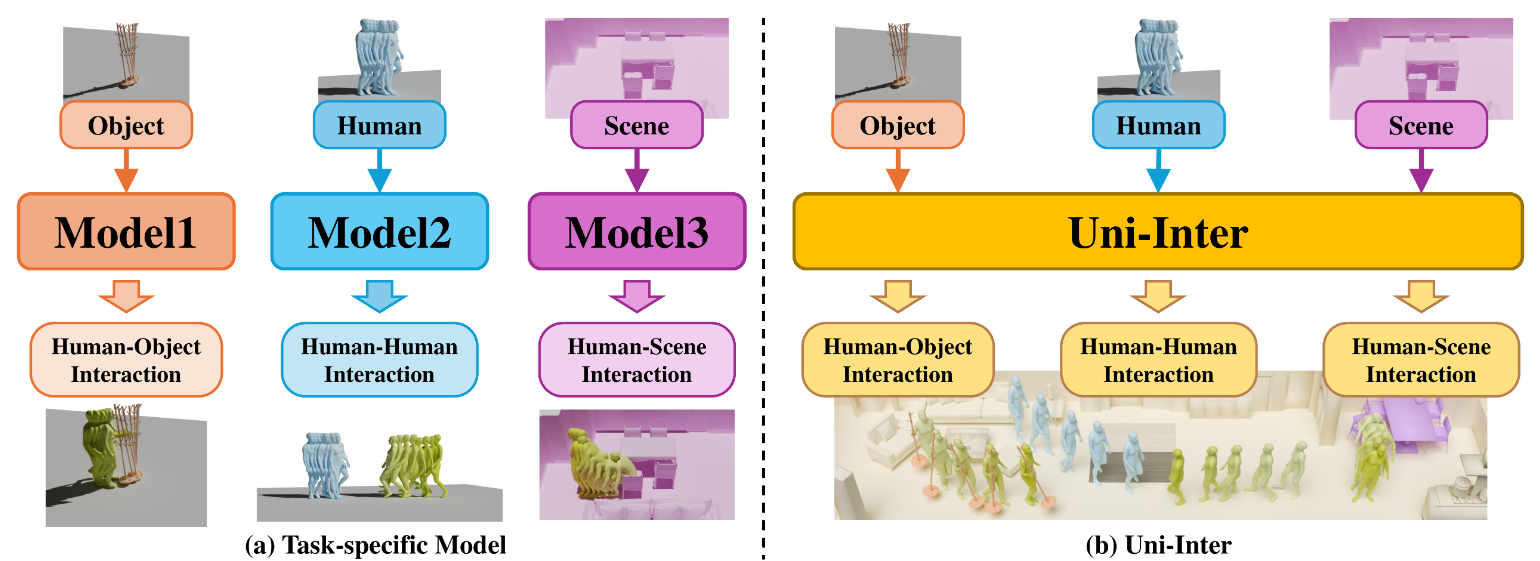
Uni-Inter 讨论的不是单一动作类别,而是交互动作生成的"碎片化"问题:不同交互(人-物、人-人、人-场景)常用不同表示、不同数据、不同模型。 论文的核心是统一交互表示:将所有参与者映射到统一体素空间(UIV),避免为不同对象写不同专用分支;并采用概率分布/概率场的预测,而非单点坐标预测,让动作生成更自然、容错更好。 这种统一表示与预测形式提升了跨交互场景的兼容性,并有利于对未见交互类型的泛化。
1. 痛点:为什么交互动作生成总是"一任务一模型"
交互带来的差异非常大:对象类型不同、接触约束不同、空间参考系不同。 传统做法往往为每类交互设计专用表示与网络,导致输出不兼容、数据难共享、调参流程割裂。
2. 统一表示:万物皆在同一体素空间
统一体素空间的关键价值是“对齐”:把人、物体、场景都放进同一坐标系,模型不再依赖人为的主语/宾语划分。 一旦空间关系被统一,很多交互问题就能用一致的方式建模。
3. 概率场预测:用‘模糊正确’替代‘精确错误’
交互动作本质上允许一定空间容错。预测概率分布而不是单点坐标,能更稳定地表达多解性,也更符合真实动作的自然性。
4. Key Insights:统一框架的价值不只在指标,更在工程与数据闭环
当输出与表示统一后,数据更容易共享,训练与评测更容易标准化。 对长期迭代的动作系统来说,这种“工程可持续性”往往比一次性的 SOTA 更重要。
English Summary
Uni-Inter aims to unify 3D human motion synthesis across diverse interaction contexts, including human-object, human-human, and human-scene interactions. Many prior approaches build separate representations and models per interaction type, making outputs incompatible and limiting data reuse.
Core Idea
Map all participants into a unified voxel space and predict interaction-relevant distributions rather than single-point targets. This representation reduces task-specific branching and provides a common interface across interaction settings.
Why This Helps
A shared spatial representation improves alignment across entities and interaction types. Distribution-based prediction naturally handles multi-modality and tolerances in contact and motion, which are common in realistic interactions.
Practical Takeaways
Unification benefits not only accuracy but also engineering scalability: shared data pipelines, shared evaluation, and easier incremental improvements. For long-term systems, a stable unified interface can be more valuable than task-specific improvements.