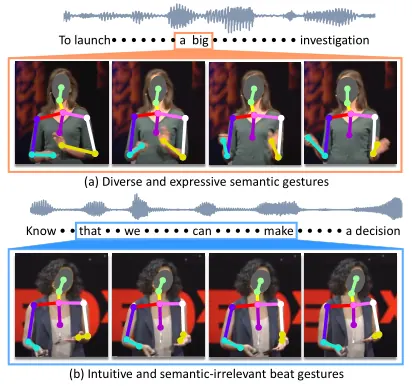
SEEG 研究 co-speech gesture generation:从语音/文本生成与讲话同步的手势序列。作者指出手势可以分成两类信号: (1)Beat gesture(节奏手势):与语音节拍强相关,结构简单、易学习; (2)Semantic gesture(语义手势):承载信息表达,受文化/个体风格影响大,时间对齐也更不稳定。 传统端到端训练往往被"更容易学的节奏信号"主导,导致生成结果动作流畅但语义贫乏。 SEEG 通过结构化解耦:分别学习节奏分支与语义分支,再融合生成完整手势,并用一个间接语义监督机制(语义子集 + 手势语义分类器)保证语义手势被真正优化。
1. 任务背景:为什么语音驱动手势总是"跟节奏摆"
在语音驱动动作生成里,节奏对齐是强、稳定、可预测的信号;但"语义对应什么手势"没有唯一标准,且受说话者风格与语境影响。 结果是:端到端模型很容易学到 beat gesture,却很难学到 semantic gesture。
2. 关键观点:把手势拆成两类信号再学习
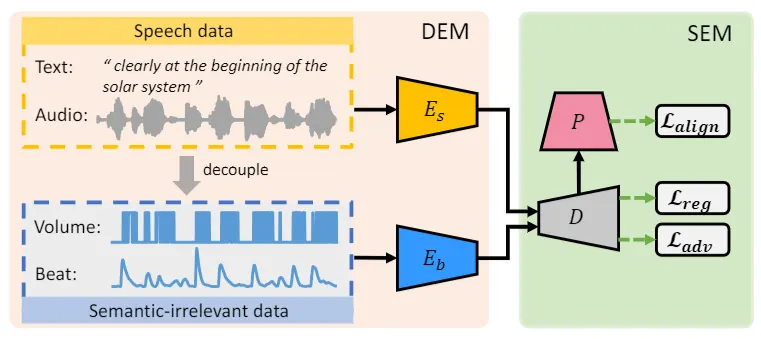
SEEG 的拆分不是为了更复杂,而是为了避免优化目标被简单信号劫持: 用独立分支分别吸收节奏与语义信息,让语义能力有"专属容量"和"专属梯度"。
3. 语义监督怎么做:不用硬定义规则,而是用“可学习的语义分类器”
直接规定“这句话必须做这个手势”几乎不可行。SEEG 的思路更工程化: 先从训练数据里选一个包含典型语义类别的小子集(例如计数、强调、态度表达等), 再训练一个手势语义分类器,把“生成手势”和“真实手势”的语义类别对齐,作为间接监督。
4. Key Insights:典型的“易学信号遮蔽难学信号”问题
SEEG 的价值在于把问题讲清楚:不是模型不够大,而是训练信号的结构导致优化倾向。 类似现象也出现在很多多模态/序列任务中:越稳定、越可预测的信号越容易主导学习。 解决方法往往不是堆模型,而是把目标拆解、把梯度路径拆开、再通过可控机制做融合。
English Summary
SEEG targets co-speech gesture generation: producing human-like gestures synchronized with speech. A common failure mode in end-to-end training is that models learn beat gestures (rhythmic motion aligned with prosody) but underfit semantic gestures that carry communicative meaning.
Problem
Beat cues are stable and easy to predict from audio, while semantic gestures are diverse, weakly aligned in time, and vary across speakers. Joint training is therefore dominated by the easier beat signal.
Core Idea
SEEG disentangles gesture generation into rhythm and semantic branches, then fuses them. A learnable semantic supervision mechanism (via a semantic subset and a gesture-semantic classifier) ensures the semantic branch receives a meaningful optimization signal.
Practical Takeaways
When a stable signal dominates training, splitting the objective and separating gradient paths often improves learning of the harder factor. For gesture generation, explicit semantic capacity and supervision are critical for avoiding "rhythm-only" outputs.