MAAL 关注机器人对 3D articulated objects(柜门、抽屉、把手等)的 affordance learning:给定物体几何(点云/mesh)以及候选交互点与动作,预测哪里能抓/推/拉(where to act)、怎么施力(how to act)以及交互是否成功(outcome)。 核心思路是把高度不平衡的"成功/失败交互"数据,重构为"成功动作是否能被模型重建"的问题:只学习成功样本,用重建误差作为质量信号;再用多模态编码器显式融合几何、交互点与动作,并引入 action memory 作为经验原型库,提升样本效率与稳定性。
1. 问题是什么:机器人为什么"知道物体是什么"却"不知道该怎么用"
识别一个物体很容易,但"正确地与之交互"很难。所谓 affordance(可供性),可以理解为:物体允许你对它做什么动作,以及哪些位置/方向是有效的。 在 articulated objects 中,这个问题更棘手:动作与结构强绑定,抓错位置/用错方向往往直接失败。
2. 关键困难:失败样本极多,直接监督会把训练拖向"暴力试错"
在仿真里随机采样交互点与动作,绝大多数会失败。这会导致训练数据高度不平衡:负样本海量、正样本稀少。 许多传统 pipeline 需要多个模块(判别器/actor-critic/多阶段训练)去逐步拟合 where/how/outcome,工程复杂且对失败分布敏感。
3. MAAL 的核心转写:把任务变成“成功动作是否可被重建”
MAAL 的关键直觉是:与其让模型直接吞下大量失败,不如只对“成功交互”建模,学习一个能够重建成功动作的表示。 这样一来,交互质量可以通过重建误差刻画:越像成功原型的动作,越容易被重建;反之重建困难。
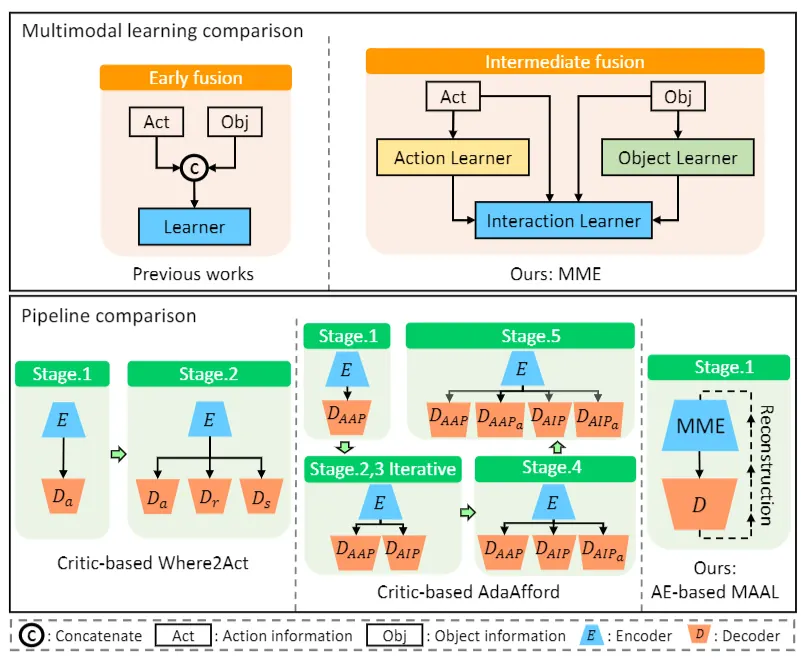
为什么 AE(Autoencoder)在这里合适
在极端类别不均衡下,AE/Memory AE 在异常检测里常用:用"正常样本"的可重建性来定义异常。 MAAL 类似地把"成功动作"当成正常样本,从而绕开了失败样本主导训练的问题,并让训练目标更干净。
4. 多模态不是装饰:几何、交互点、动作属于不同统计结构
输入包含点云/几何、候选交互点、机械臂动作参数等,这些模态分布差异很大。 直接 concat 往往学得不稳定;MAAL 通过多模态编码器更结构化地融合信息,使表示更可控、更能泛化。
5. Action Memory:把"成功经验"显式存成可检索原型
将成功动作模式存入记忆库,相当于为重建提供更好的参考原型:模型不需要从零生成所有成功动作,而是更像从原型空间中选择/组合。 这在数据有限、物体结构多样时尤其有效。
6. Key Insights:MAAL 更像是在改"学习信号",而不是改网络结构
这篇工作的价值不只在于提出一个 AE+MM 的模型,更在于把 affordance learning 的监督信号重新组织了: 把“失败占主导”的试错监督,转成“成功可重建性”的结构监督。 对很多高度不平衡的交互/控制问题,这种信号改写往往比堆网络更有效。
English Summary
MAAL studies affordance learning for 3D articulated objects, where an agent must decide where to interact and how to apply an action to achieve a successful manipulation outcome. A key challenge is extreme class imbalance: random interactions fail most of the time, so naive supervision can be dominated by failures.
Core Idea
MAAL reframes the learning signal by modeling successful interactions as the "normal" set and using reconstructability as a quality indicator. The approach emphasizes representing and reconstructing successful action patterns rather than directly learning from a sea of failures.
Why This Helps
By anchoring training on successful behaviors, the model avoids unstable gradients caused by overwhelming negative data. The method also benefits from structured multimodal fusion (geometry, interaction point, action parameters), which improves stability and transfer across object instances.
Practical Takeaways
In highly imbalanced interaction datasets, changing the supervision target can be more effective than increasing model complexity. Modeling "good" behaviors explicitly often yields a cleaner objective and better sample efficiency.