AntEval 关注的是"如何评估多 Agent 对话质量",而不是直接改进 Agent。 作者将社交互动质量拆成两条主轴: Informativeness(信息量):对话是否真的传递了可用的新信息,而不是礼貌寒暄; Expressiveness(表现力):对话是否表达了真实意图/态度/隐含语义,并能被他人理解。 方法上,信息量通过让各 Agent 总结 key points 并计算一致性来衡量;表现力则借助 TRPG 场景中的 Skill Check:引入一个 Virtual DM 根据对话预测意图判定,与真人对话的可预测性差距越小,说明互动越接近真实。
1. 痛点:多 Agent "聊得像在客套"
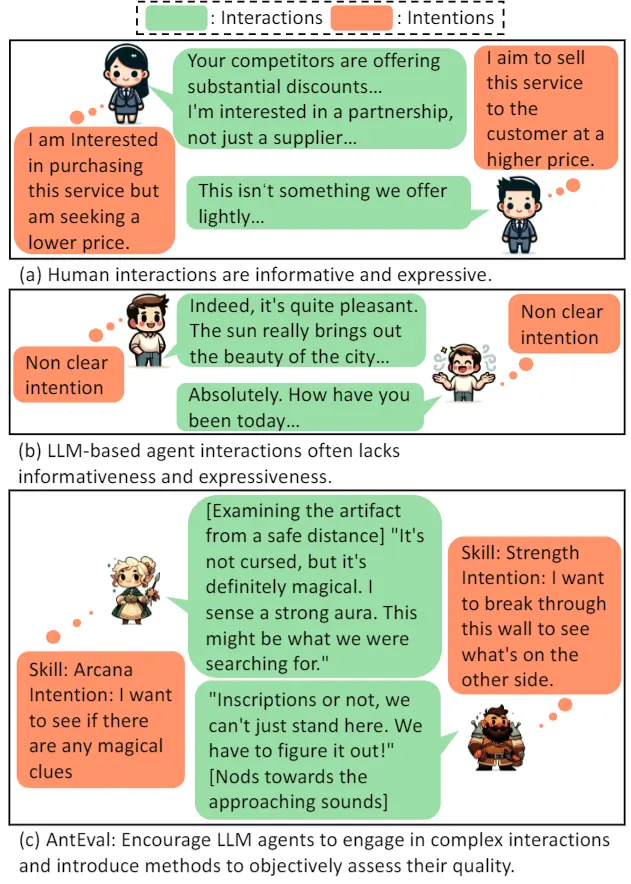
多 Agent 系统很容易产生大量礼貌寒暄,看起来流畅但缺乏内容。传统评估往往只看任务是否完成,却无法反映互动是否真实、有信息价值。
2. 两个维度:信息量 vs 表现力
Informativeness 更像"知识同步效率";Expressiveness 更像"意图沟通能力"。 把两者分开非常关键,因为两种失败模式不同: 有的对话信息量低但很自然;有的对话信息量高但过于直白(像把意图写在台词里)。
3. 为什么用 TRPG:Skill Check 提供天然意图标注
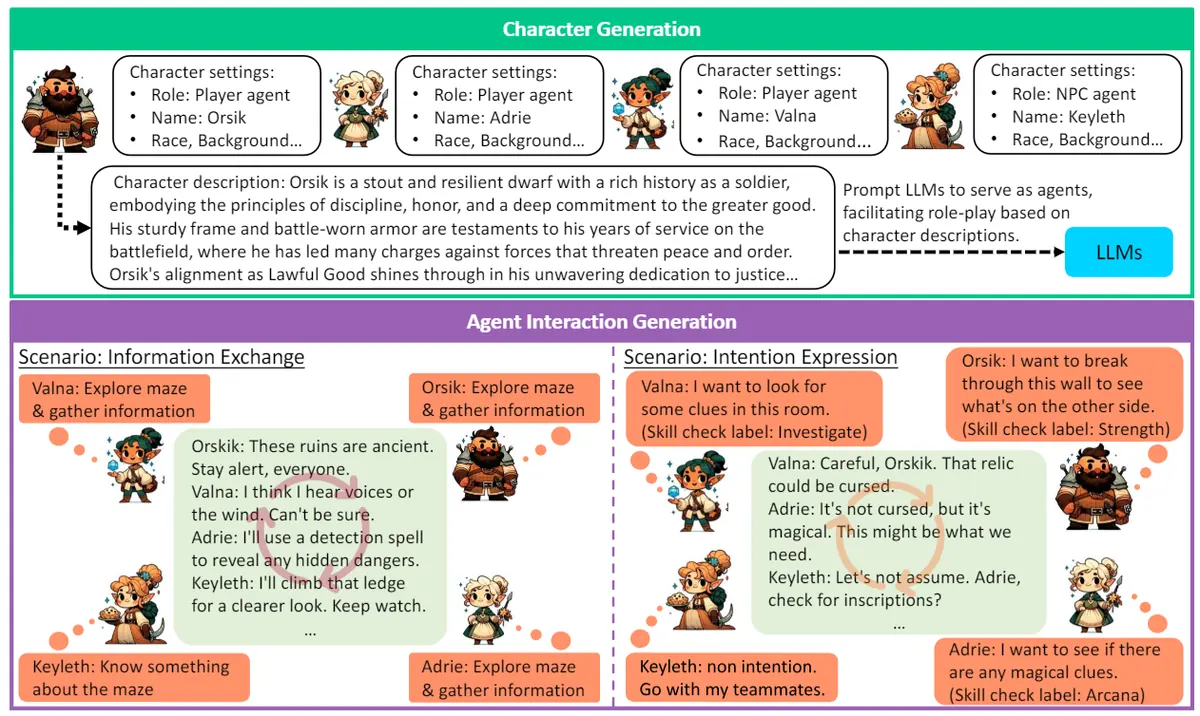
TRPG 场景里,玩家行为背后通常对应明确的 skill check(说服/潜行/调查等)。 这相当于为"隐含意图"提供可量化的监督信号,使得 Expressiveness 的评估可落地。
4. Key Insights:评估比优化更先行,且必须可诊断
对多 Agent 而言,任务完成只是结果指标,无法诊断“为什么能/不能完成”。 AntEval 的拆维度思路更像给系统做体检:信息同步是否发生、意图沟通是否成立。 这种可诊断性会直接影响后续的训练策略与数据构造。
English Summary
AntEval proposes a quantitative evaluation framework for social interactions among multiple agents. It targets a common failure mode: conversations that are fluent but low in informational content and weak in intention expression.
Dimensions
The framework separates interaction quality into two axes. Informativeness measures whether agents exchange actionable new information rather than polite filler. Expressiveness measures whether latent intentions and social signals are communicated in a way that others can infer.
Why TRPG Helps
TRPG-style scenarios provide structured, interpretable intention signals via skill checks. This makes expressiveness measurable without relying on purely subjective judgments.
Practical Takeaways
For multi-agent systems, outcome-only metrics are insufficient. Diagnostics that disentangle information exchange from intention expression are crucial for guiding data collection and training.